Perceptual Deep Depth Super-Resolution
1Skolkovo Institute of Science and Technology2Higher School of Economics3New York University
International Conference on Computer Vision 2019
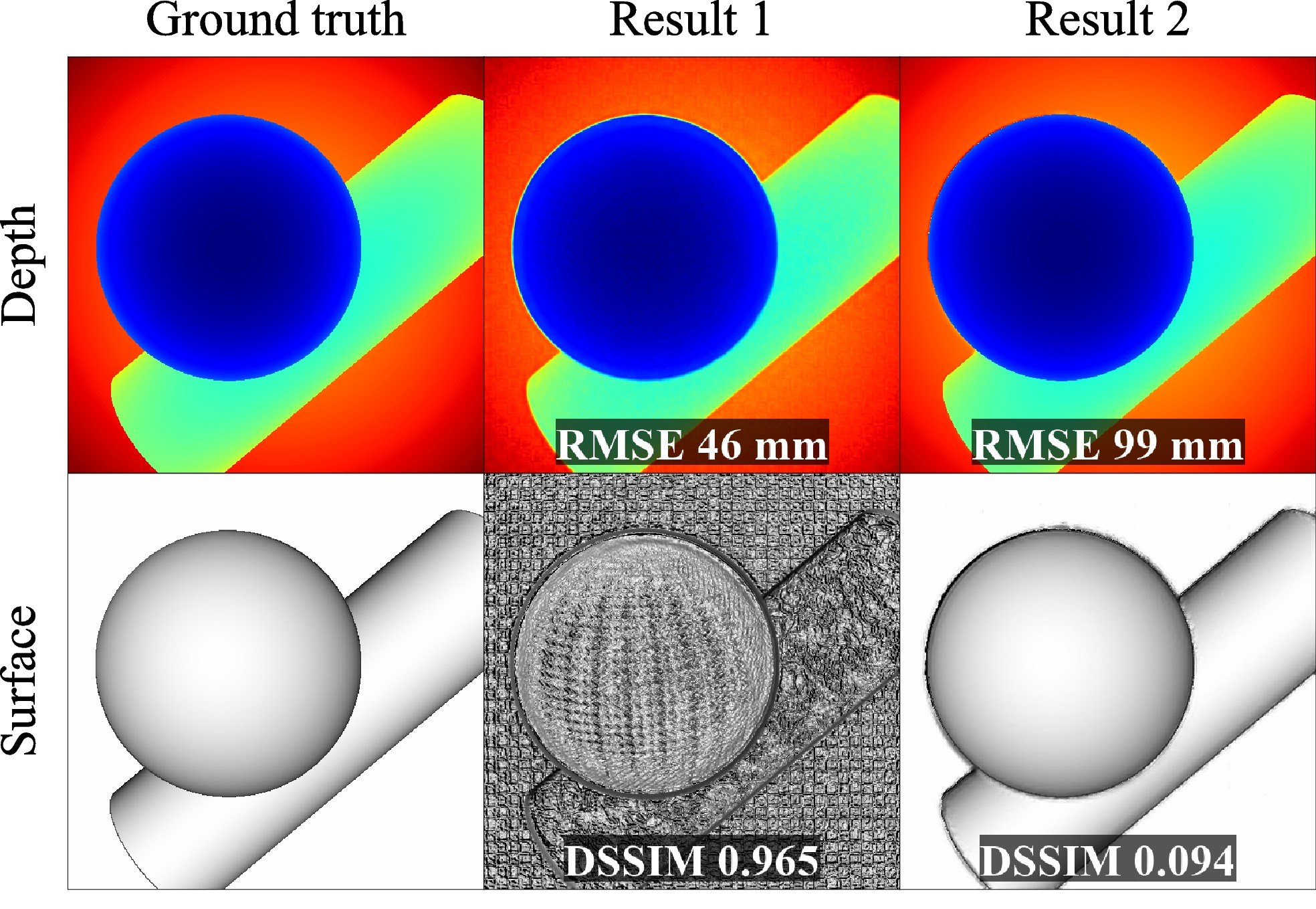
Visually inferior super-resolution result in the middle gets higher score according to direct depth deviation but lower score according to perceptual deviation of the rendered image of the 3D surface. While the surfaces differ significantly, the corresponding depth maps do not capture this difference and look almost identical.
Abstract
RGB-D images, combining high-resolution color and lower-resolution depth from various types of depth sensors, are increasingly common. One can significantly improve the resolution of depth maps by taking advantage of color information; deep learning methods make combining color and depth information particularly easy. However, fusing these two sources of data may lead to a variety of artifacts. If depth maps are used to reconstruct 3D shapes, e.g., for virtual reality applications, the visual quality of upsampled images is particularly important. The main idea of our approach is to measure the quality of depth map upsampling using renderings of resulting 3D surfaces. We demonstrate that a simple visual appearance-based loss, when used with either a trained CNN or simply a deep prior, yields significantly improved 3D shapes, as measured by a number of existing perceptual metrics. We compare this approach with a number of existing optimization and learning-based techniques.Materials
Contact
If you have any questions about this work, please contact us under adase-3ddl@skoltech.ru.